
CrowdStrike
How a Programming Error Led to the Largest IT Outage in History, Costing Companies $5 Billion


Unless you've been living under a rock, you've heard of the CrowdStrike incident, which cost Fortune 500 companies over $5 billion in direct losses. What many hacker groups have tried to achieve was inadvertently accomplished by the very company that protects us from them. The error was simple but had devastating effects.
The impact was far-reaching.
People had to reschedule medical procedures
Travelers missed their flights
Public transport was affected
And the list goes on.
This disruption came from affecting just 8.5 million Windows devices. It shows how vulnerable we are to computer systems and how easily our digital-dependent lives can be disrupted.
In this post, I'll explore:
CrowdStrike and how it became a big player in cybersecurity
The technical cause of the incident
Key lessons we can learn from this event
What is CrowdStrike?
CrowdStrike was founded in 2011 by George Kurtz (CEO), Dmitri Alperovitch, and Gregg Marston. They envisioned building a more adaptable approach to security threats.
Traditional vendors like McAfee relied on signature-based solutions that required downloading new signatures to protect against threats. This approach was ineffective since attackers could quickly develop new variants to bypass the security software.
CrowdStrike's innovative idea was to create behavioral analysis that monitored not just individual machines but entire corporate fleets. This approach could detect anomalies even when facing unknown threat vectors.
The Falcon Agent & Cloud Architecture
Their first step was developing the lightweight Falcon agent for client machines, which consumed far fewer resources than traditional security scanners. The heavy lifting happens on their cloud platform, which ingests and analyzes threat data.
This architecture introduced a new concept:
The platform continuously updates with knowledge about potential threats, providing immediate client protection.
Deep OS Integration
For this system to work at scale, the Falcon agent requires low-level access on each machine. It integrates closely with the operating system's kernel—the core that controls access to hardware resources like memory and network.
This deep integration ensures the Falcon agent can monitor all system events, making it more difficult for attackers to circumvent.
Over the years, CrowdStrike has enhanced its platform with numerous security modules, as shown in the screenshot.
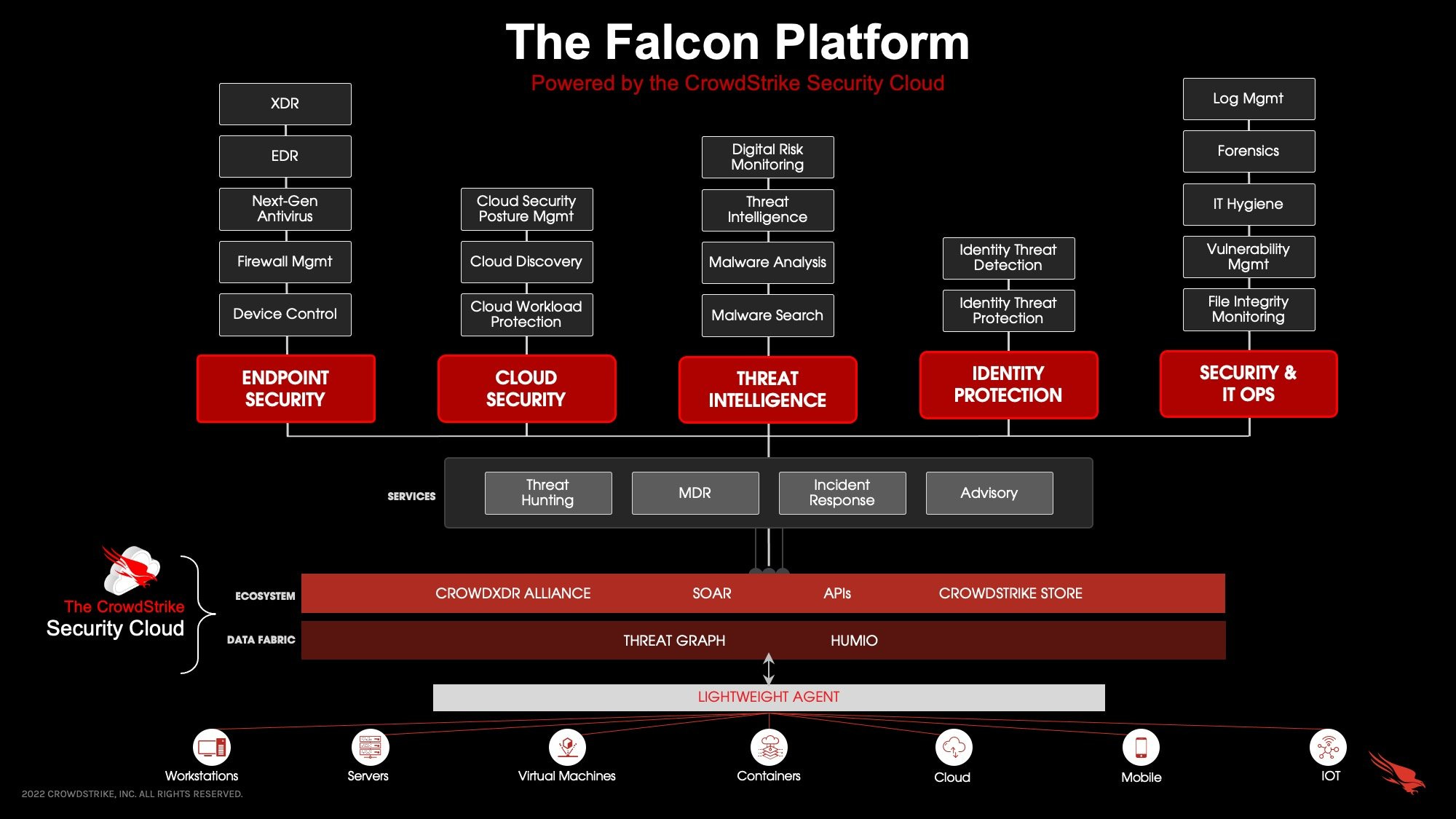
Their promise is simple: prevent all types of attacks with a single solution—an appealing proposition for many companies.
A Track Record of Success
CrowdStrike's success stems not only from its architecture but also from its track record of uncovering major attacks in its early days.
The company gained prominence by:
Identifying North Korean hackers behind the Sony Pictures breach
Exposing the VENOM flaw in 2015
Uncovering Chinese hackers targeting technology and pharmaceutical companies
These achievements established their credibility in both preventing and detecting attack vectors.
Why This Matters
Why is this significant? Consider this:
Cybercrime losses are projected to reach $10.5 trillion by 2025.
Beyond financial impact, a public security breach can devastate a company's reputation. This reality drives many organizations to invest in comprehensive solutions like CrowdStrike to protect their assets and brand image.
While the premium pricing of cybersecurity platforms may seem high, it's justified when considering potential losses. Though not every company needs this level of protection, it functions like insurance—you pay for it, hoping you'll never need it.
Technical details
In this section, we'll examine the technical details of the Falcon suite. Since there's no official whitepaper containing all this information, this analysis is based on research from multiple sources.
Cloud-First Security Architecture
As mentioned earlier, Falcon uses a cloud-first architecture to protect against real-time threats. This means all protected machines must maintain a connection to Falcon's data centers, which are hosted on AWS.
Handling Massive Data Ingestion
The infrastructure's first challenge is data ingestion. Falcon uses Kafka-based event streaming to handle massive peak loads of 3.2 PB of daily telemetry. Their capabilities expanded in 2021 when CrowdStrike acquired Humio, a leading cloud log management and observability tool, enabling them to index log data across various environments.
Threat Detection & Correlation
While collecting data with low latency is crucial, the next challenge is correlating patterns with potential attacks. For this, they developed the Threat Graph® Correlation Engine, which:
Processes over 2 trillion security events weekly
Monitors over 25 million endpoints
Identifies emerging attack patterns using machine learning models
Optimizing Performance
To optimize performance, not all requests go to a central platform. Similar to CDNs, regional nodes synchronize threat indicators, improving response times.
While CrowdStrike's platform offers many additional capabilities and technical features, we've focused on these core elements to explain its widespread adoption and provide context for the events that led to the incident.
Incident
The Falcon suite consists of sensors that deliver data for machine learning and customer system protection. These sensors are installed on machines to aggregate various types of data, including logs, memory, and pipes. However, they don’t simply transmit raw data to the cloud—they also handle filtering, aggregation, and local caching.
Threat detection occurs both in the cloud and locally. Local processing is crucial because sending all data continuously would overload the system. Instead, the sensors intelligently decide which information is necessary to detect attack vectors.
Since threat information evolves constantly, CrowdStrike needs to adapt quickly. They achieve this through Rapid Response Content, which allows them to update detections, gather telemetry, and identify indicators without modifying the sensor’s code.
The Role of Channel Files & Content Interpretation
Changes to Rapid Response Content are delivered through Channel Files, which are processed by the sensor’s Content Interpreter. This system uses a regular-expression-based engine to analyze and respond to new threats. Different Template Types—such as those for memory or pipes—define the kinds of data being processed.
When CrowdStrike discovers a new threat vector, it can update sensors almost immediately.
The faster the update, the sooner systems are protected.
The February 2024 Update & Dormant Issue
In February 2024, CrowdStrike introduced a new Template Type to monitor threats that exploit named pipes and other Windows interprocess communication (IPC) mechanisms. While this update was tested and integrated, it remained inactive.
Each Template Type consists of input parameters that guide how the Falcon agent analyzes data. Typically, a Content Validator ensures data correctness, while a Content Interpreter processes the inputs. The IPC Template Type defined 21 input parameters, but the Content Interpreter only expected 20.
At first, this wasn’t an issue. Since the new Template Type wasn’t actively used, the discrepancy went unnoticed. The system functioned normally because the 21st parameter was skipped due to wildcard matching.
The July 19, 2024 Deployment – When Everything Broke
On July 19, 2024, two additional Template Instances were deployed that relied on the 21st input parameter—and that’s when everything went wrong.
Although the Content Validator correctly validated all 21 inputs, the Content Interpreter only received 20. When it attempted to access the missing 21st parameter, it caused an out-of-bounds read, which crashed the machine.
Because Falcon is deeply integrated with the kernel, this didn’t just crash the program—it crashed the entire machine. Worse, since Falcon loads early in the boot process to protect against attacks during startup, every reboot triggered another blue screen, trapping machines in an endless blue screen of death (BSOD) cycle.
A Simple Mistake with Massive Consequences
The massive outage was caused by a basic programming error—a mismatch between input parameters and program expectations.
An out-of-bounds error like this is a fundamental programming mistake—something taught in university courses—yet it led to the largest outage ever recorded.
Why Didn’t CrowdStrike Catch This Issue?
The Incident Report identified several failures:
No validation at sensor compile time – The system lacked safeguards that could have detected the issue before deployment. This has since been patched.
No runtime out-of-bounds checks – Proper logging and validation at runtime would have revealed the mismatch before it caused an outage.
Incomplete testing – New Template Types were tested, but only on some parameters, focusing on security-related data flow rather than all 21 inputs.
The Content Validator missed the mismatch – It checked for file correctness but failed to verify compatibility between the Content Interpreter and the 21-parameter input.
The 21-parameter Channel File wasn’t tested before deployment – No safeguards were in place to catch the discrepancy.
No staged deployment process – In a cloud environment, rolling out updates without gradual testing is risky. Staging updates could have prevented the widespread failure.
A proper staged rollout with continuous monitoring would have allowed CrowdStrike to detect the issue before it brought down millions of machines.
Mistake
In hindsight, the issue seems like a glaring problem that should have been caught and properly tested. How could a company of CrowdStrike’s size miss something so fundamental?
Looking closer, Channel Files function similarly to Configuration Files—they change behavior without modifying the actual code. Throughout my career, I’ve often heard the phrase, “It’s just a configuration change,” which leads many to assume these changes are less intrusive than code modifications. However, when analyzing large-scale incidents, configuration changes frequently emerge as the root cause of major failures.
Testing is also a significant investment. While developing software and new features generates immediate value, testing does not provide instant returns. Software can function without issues for extended periods, particularly when complexity increases gradually. However, comprehensive testing is time-consuming, and covering every possible scenario is impossible.
With limited budgets, companies must strike a balance—testing real-world scenarios while also developing mitigation strategies to minimize potential failures. CrowdStrike’s biggest mistake was deploying a change without a staged rollout. By affecting all customers simultaneously, recovery became extremely complex.
A staged rollout allows for production testing and quick rollbacks—preventing widespread disruptions. For SaaS businesses pushing updates to all customers at once, this simple step is critical to avoid becoming the next CrowdStrike.
Impact and Recovery
The impact was devastating, affecting around 8.5 million Windows devices across various industries, with healthcare and aviation hit particularly hard. While most services were restored within 24 hours after CrowdStrike released a fix bulletin, Delta Airlines was a notable exception. Delta took nearly a week to recover, canceling numerous flights during this period.
Why did Delta struggle while its competitors recovered in just 24 hours? The issue stemmed from outdated infrastructure and a heavy reliance on Windows machines. Delta had to manually reboot and fix approximately 40,000 devices. With critical infrastructure affected and no automatic recovery tools or backups to restore systems quickly, the airline faced a significant challenge.
In contrast, Delta’s competitors operated hybrid data centers with backups and automation, reducing the need for manual intervention.
Delta’s case is an extreme example of how severe the impact could be. The incident also created a particularly difficult weekend for system administrators across affected organizations. Many companies had Falcon installed not just on servers but also on employee machines, requiring each device to be rebooted and cleaned of the faulty Channel File.

There were three possible fixes available:
Recover the system with a backup
Reboot the system in safe mode and delete the file
Reboot the system multiple times until Falcon potentially updates the Channel Files and recovers itself
Simple enough, right? Now, imagine doing this manually on thousands of devices across your company.
A significant challenge emerged with encrypted disks—entering safe mode requires an unlock key. Some companies had stored these keys on Windows machines that were themselves affected by the CrowdStrike issue.
This serves as a crucial lesson: avoid relying on a single system, as it creates a dangerous dependency. These critical keys should be stored in a separate password manager and protected by independent security measures.
Money loss
Losses are estimated at $5 billion for Fortune 500 companies alone—a devastating impact. The reputational damage during this period was severe. CrowdStrike faced intense consequences, with its share price dropping 14% immediately and declining nearly 50% by August 2024 as investors worried about customer churn, litigation costs, and reputational damage.
However, customer churn remained minimal thanks to transparent communication and an excellent document detailing the outage and preventive measures. Apart from Delta, there were no significant litigation costs. The company's share price has since recovered, surpassing pre-incident levels.

This incident raises important questions about the potential consequences of such outages for companies. While CrowdStrike emerged stronger, their experience shouldn't be seen as a universal template. The impact of such an incident depends heavily on your customers and their ability to switch to competitors.
Overall, the outage strengthened CrowdStrike's competition. The following market share figures, compiled from various news sources, show the shift in market dynamics, though these numbers should be considered approximate.
Summary
CrowdStrike, a leading cybersecurity company, experienced a catastrophic outage in July 2024 due to a simple programming error. A mismatch between input parameters in their Rapid Response Content system caused widespread system crashes, affecting 8.5 million Windows devices and resulting in estimated losses of $5 billion for Fortune 500 companies.
Key Takeaways
A basic array bounds error in configuration files led to the largest cybersecurity outage ever recorded
The incident particularly impacted healthcare and aviation sectors, with Delta Airlines taking nearly a week to recover due to outdated infrastructure
Despite the severe impact, CrowdStrike's transparent communication helped maintain customer trust
Configuration changes often considered less risky than code changes, can have devastating consequences without proper testing and staged rollouts
The incident changed the cybersecurity market, with competitors like Microsoft, SentinelOne, and Palo Alto gaining market share
Critical lesson: Always implement staged deployments and maintain independent backup systems for critical infrastructure