
First Look: The Shifting LLM Landscape of 2025 - Speed, Scale, and Innovation
An in-depth analysis of the latest developments in Large Language Models, examining the impact of new players like DeepSeek R1, Mistral's le Chat, and Gemini 2.0 on the market landscape.

The LLM market has seen significant movement since DeepSeek R1's release. There are concerns about China becoming a serious competitor to US companies, leading to discussions about potential usage bans.
While valid security concerns persist, the notion that Europe isn't a market player was recently disproven by Mistral's release of le Chat—an underreported development with some interesting details. Additionally, Google has made their Gemini2.0 version publicly available without requiring a premium account, offering an impressive context window.
Which LLM vendor should engineers choose today? To address this question, I'll present a simplified comparison of:
Mistral le Chat
Gemini
Claude
DeepSeek R1
OpenAI o3 mini
through a mini-game created entirely by each LLM, along with standard coding comparisons.
Further impact of DeepSeek R1
The release of DeepSeek R1 caused significant movement in the market. Major US players were caught off guard, though this increased competition benefited customers. For instance, OpenAI suddenly granted me access to their OpenAI o1 and o3-mini APIs, which had previously been restricted (see screenshot).
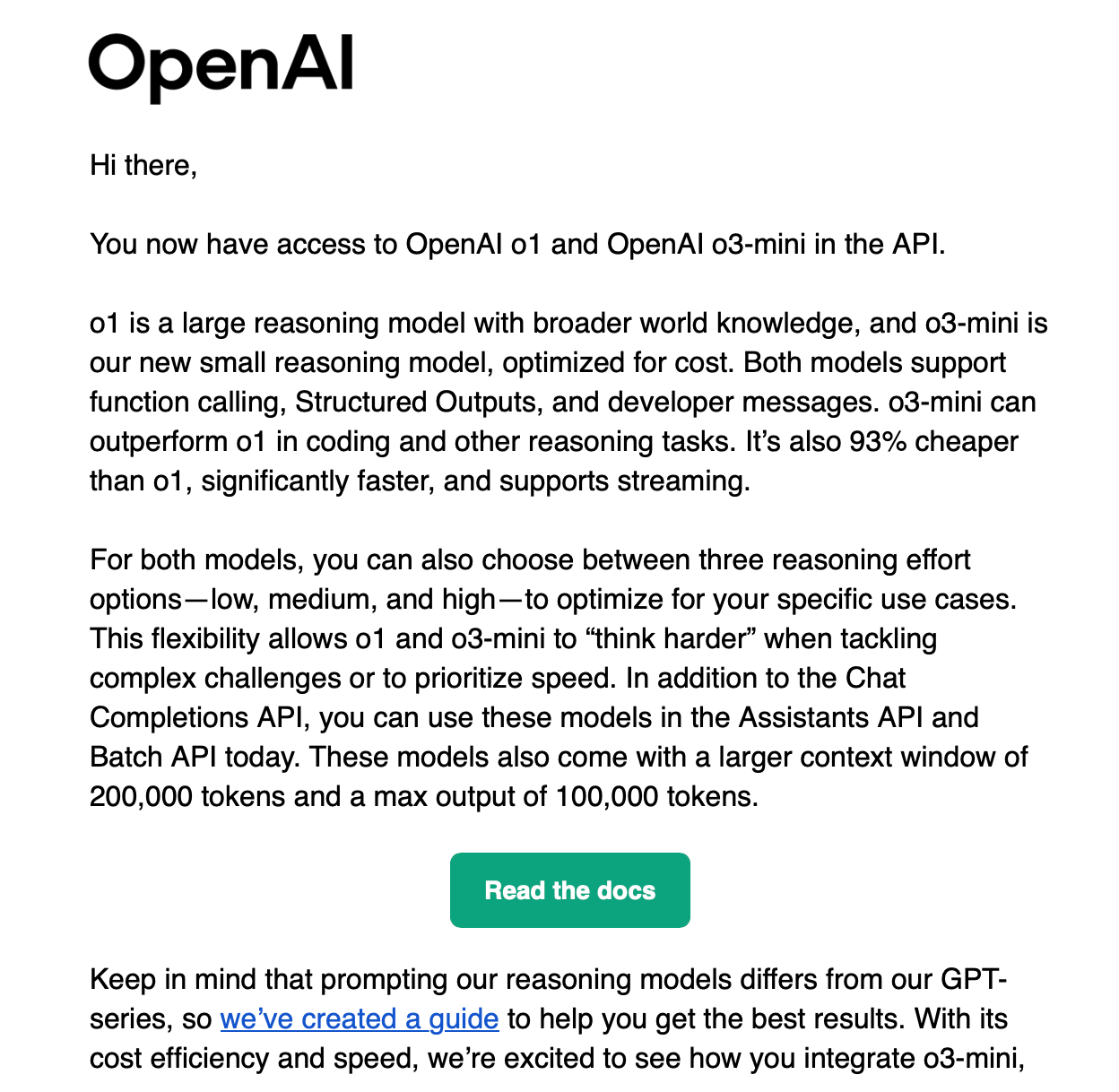
Not only that, if you're a free ChatGPT user, you may have noticed the new "Reason" button for answers. This feature wouldn't have been released so quickly if not for DeepSeek R1's launch.
Interestingly, many security companies have scrutinized DeepSeek—I wonder if they apply the same scrutiny to OpenAI. They uncovered two major security issues:
US cybersecurity company Wiz discovered an exposed data leak. The leak was in a publicly accessible ClickHouse database that granted full control over database operations, including access to internal data. The database contained chat history, backend data, log streams, and API secrets. After Wiz contacted them, DeepSeek promptly secured the database.
The second security issue, published three days ago by NowSecure, revealed multiple security and privacy flaws in DeepSeek's iOS mobile app. They discovered several critical vulnerabilities that are quite alarming. The app transmits sensitive data without encryption or uses weak, hardcoded encryption keys. It also employs extensive data collection and fingerprinting, sending data to China under ByteDance's control. Due to these high risks, I agree with NowSecure's recommendation to uninstall the DeepSeek iOS app if you have it.
Mistral le Chat
When discussing LLMs or AI, European companies are often overlooked. One significant player with many interesting developments is Mistral, which originated in France. Mistral recently updated its chatbot, le Chat, which is lightning-fast. This isn't an exaggeration—it can generate responses at up to 1,000 words per second, making it 10 to 13 times faster than Claude or ChatGPT, as demonstrated in the video.
Speed isn't everything, but the new chatbot also features:
Web search
In-place code execution
Image generation powered by Black Forest Labs Flux Ultra
It's a highly competitive product that I recommend trying.
What's more interesting is the hardware they use to achieve this speed. A "silent" NVIDIA competitor appears to be the first that could break the glass ceiling: Cerebras, a California-based company whose WSE-3 processor surpasses all others in AI performance. The remarkable aspect is that everything is integrated into a single processor with a massive 44-gigabyte on-chip memory. Their inference data shows performance up to 70x faster than any GPU cloud. For small-scale environments, everything is contained in the CS-3, a rack-mountable computer. If this company can finalize its IPO, which has been in progress since last year, it could significantly impact NVIDIA's stock price—assuming they can mass-produce and sell these products. Currently, the process is delayed as the U.S. national security reviews UAE's G42's minority investment in the chipmaker. This development could be transformative, especially if they can create smaller, more affordable CS-3s with lower energy consumption.
Gemini 2.0
Google initially appeared caught off guard by OpenAI's emergence, and this perception has persisted—but Gemini 2.0 is changing that narrative. It's now available to everybody and features two notable models: Gemini 2.0 Flash and Gemini 2.0 Flash Lite, which are both fast and 90% cheaper than competitors. While GPT-4o costs about $10 per million tokens, Gemini 2.0 Flash costs just $0.40 per million tokens, with Flash Lite being even cheaper. What's truly remarkable is the context window—the amount of information that the LLM can store and process. While DeepSeek has a 128k context window and o3 has 200k, Gemini 2.0 Flash boasts 1 million, allowing it to handle 100k lines of code. The Pro model pushes this even further, handling up to 2 million.
This advancement poses a serious challenge to OCR software tools in terms of pricing, speed, and accuracy. According to this blog post, 2.0 Flash processes 6,000 pages per dollar with near-perfect accuracy. If this trend continues, traditional OCR software may become obsolete as LLMs offer a more user-friendly alternative.
Deploying models locally
As written in the deep dive into DeepSeek R1, you can deploy models locally—a viable approach for some industries. The main challenge is that you either need access to large GPU clusters (potentially Cerebras chips in the future) or must rely on distilled models.
A distilled model is like a student learning from a teacher (the larger model). It uses lossy compression, meaning both accuracy and zero-shot performance decrease. More concerning is that errors in the larger model can become amplified in the distilled version. If you're running a distilled version of DeepSeek R1 and getting poor results, these limitations may be the cause. Most online comparisons focus on full models rather than distilled versions, so you'll need to test the distilled versions specifically for your use case. While distilled models might suffice for some applications, it's crucial to understand they're not equivalent to their full-sized counterparts.
Is there hope? Yes—dynamically quantized models are emerging as a solution. Instead of compressing the entire model, they selectively compress different components. Take the DeepSeek-R1 dynamic from unsloth, which selectively quantizes (compresses) layers. This approach helps address the poor response rates often seen in distilled models. However, if you choose this path, expect to extensively test various combinations of models, memory configurations, CPUs, and possibly GPUs to find the right balance for your needs. The situation should improve within the next year or two as inference costs decrease or new chips and memory solutions emerge.
Even Apple has struggled with this challenge. Their Apple Intelligence system, which runs locally on MacBooks and iPhones, had to be disabled for certain tasks due to poor performance. This is particularly concerning since it failed at simple operations like message summarization.
Comparisons
With all the developments happening and likely to continue throughout 2025, we're witnessing a fascinating race and intense competition in the LLM space. Maintaining a clear overview and determining the right time to switch models is challenging. The pace of innovation is too rapid for most companies, raising questions about potential gains from transitions. Interestingly, models are carving out distinct niches: le Chat excels in speed (though this advantage, likely due to Cerebras, may not be sustainable), Gemini offers unmatched context windows and competitive pricing, and DeepSeek has emerged as a formidable competitor with a robust open model—all alongside established players like Anthropic, OpenAI, and Meta.
Since this newsletter focuses on software, let's examine code-related comparisons. Several leaderboards conduct blind comparisons where users work with LLM models without knowing which one they use, eliminating potential bias. One excellent resource is lmarena, which provides these comparisons. While Gemini-2.0-Flash-Thinking currently leads overall, the rankings shift when examining specific coding tasks.
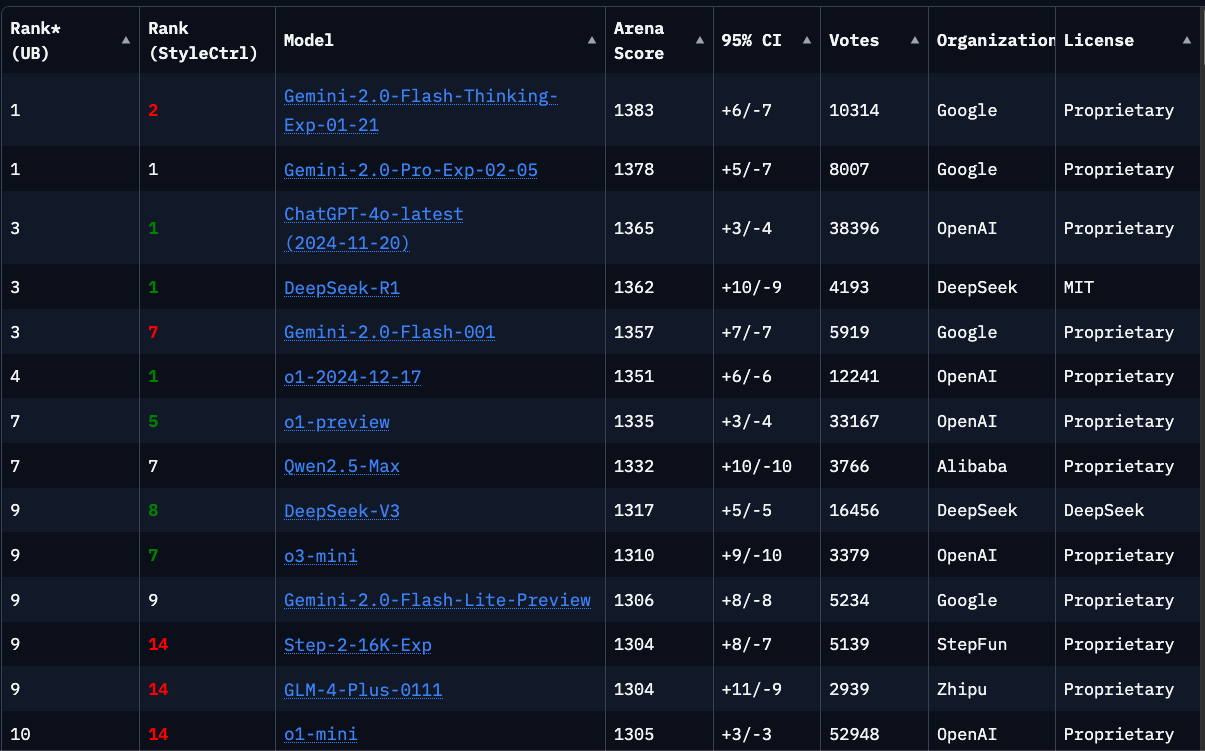
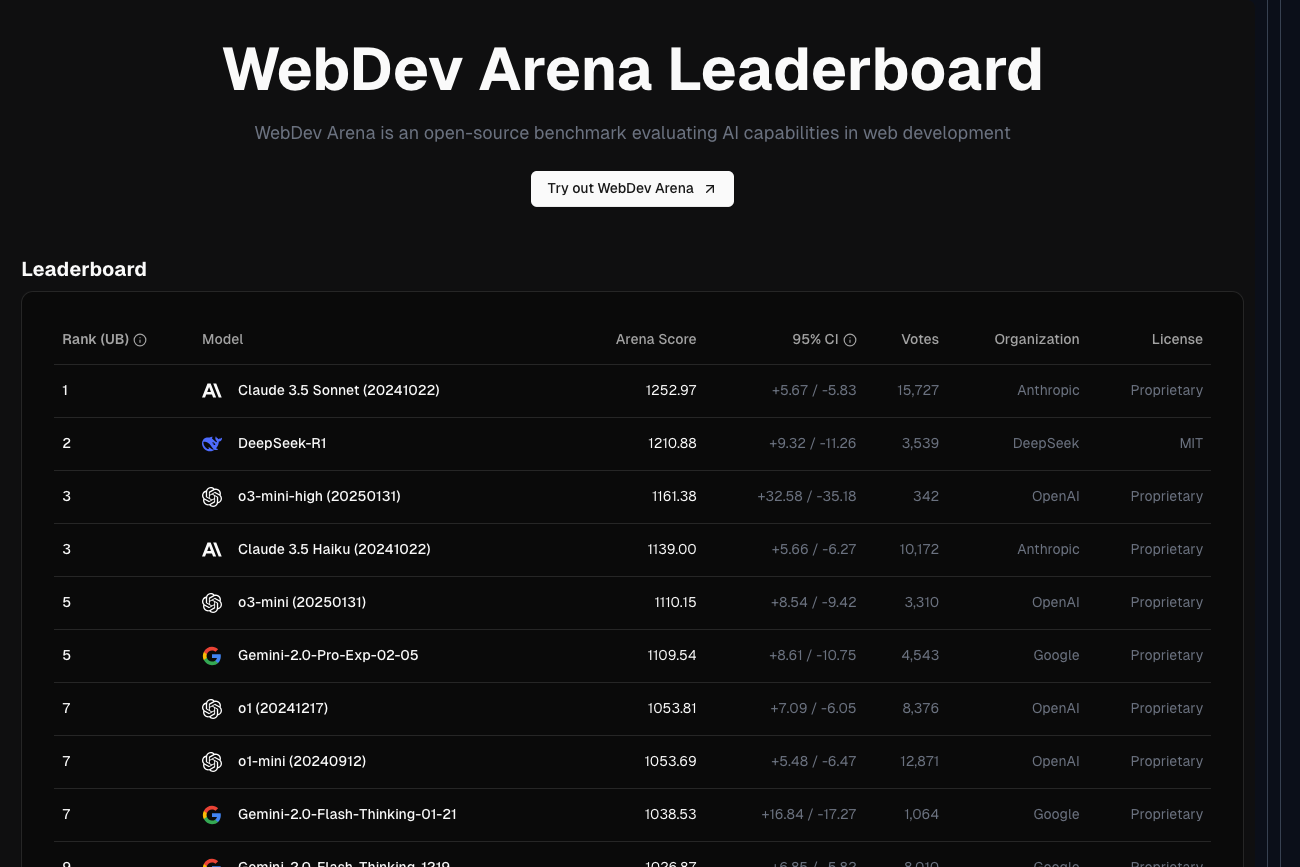
For general coding tasks, Gemini-2.0-Pro takes the lead, while Claude 3.5 dominates the WebDev Arena, which focuses on web development capabilities.
For image generation, current rankings show Recraft AI in the lead, followed by Black Forest (available through Mistral le Chat) and Google.
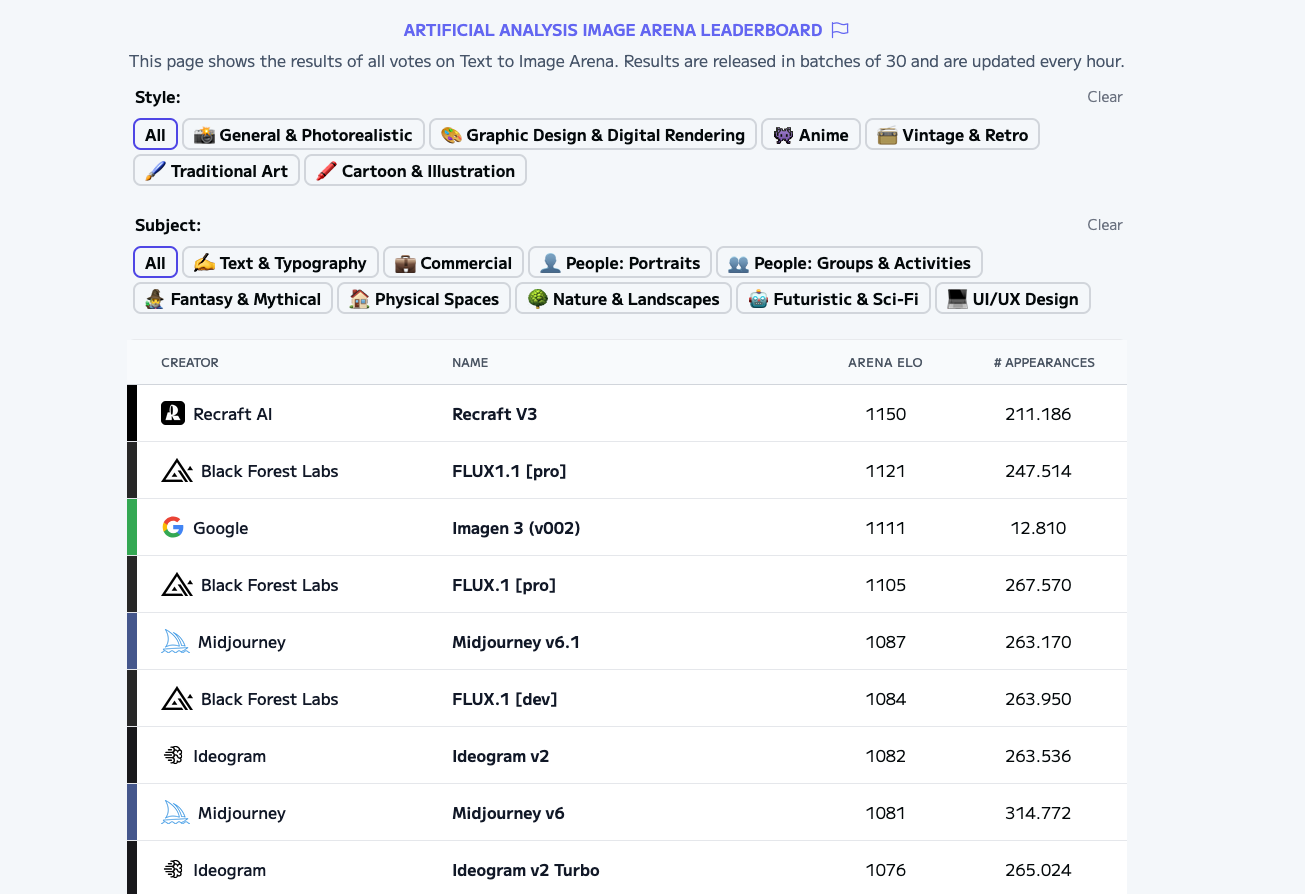
Keep in mind that these leaderboard positions can shift with each major vendor release, so chasing the top spot isn't a sustainable strategy. Instead, focus on understanding which model best suits your specific task. If you're conducting research and have flexibility in your choice, I recommend experimenting with different models.
Flappy Bird test
To compare the different LLMs, I used the unsloth example to create a Flappy Bird game in Python with the prompt below:
Create a Flappy Bird game in Python. You must include these things:
You must use pygame.
The background color should be randomly chosen and is a light shade. Start with a light blue color.
Pressing SPACE multiple times will accelerate the bird.
The bird's shape should be randomly chosen as a square, circle or triangle. The color should be randomly chosen as a dark color.
Place on the bottom some land colored as dark brown or yellow chosen randomly.
Make a score shown on the top right side. Increment if you pass pipes and don't hit them.
Make randomly spaced pipes with enough space. Color them randomly as dark green or light brown or a dark gray shade.
When you lose, show the best score. Make the text inside the screen. Pressing q or Esc will quit the game. Restarting is pressing SPACE again.
The final game should be inside a markdown section in Python. Check your code for errors and fix them before the final markdown section.
I tested the prompt with six different LLMs: Mistral le Chat, DeepSeek R1, OpenAI o3 mini, Gemini 2.0 Flash, Gemini 2.0 Flash Thinking, and Claude 3.5. All the code samples are available here.
I chose Python for this test since LLMs generally excel at it, and Flappy Bird is simple enough to implement in a single attempt. Let's analyze the results:
Nearly all LLMs successfully created a functional game. Mistral has a bug when losing that creates an endless loop, requiring a game restart. Also, le Chat was not the fastest because it was unable to enable the Flash functionality, possibly because the input text was long. Gemini 2.0 Flash produced unrunnable code due to compilation errors. From a functional perspective, according to Sonarcloud measurements, Gemini 2.0 Flash Thinking proved the fastest while delivering high-quality code.
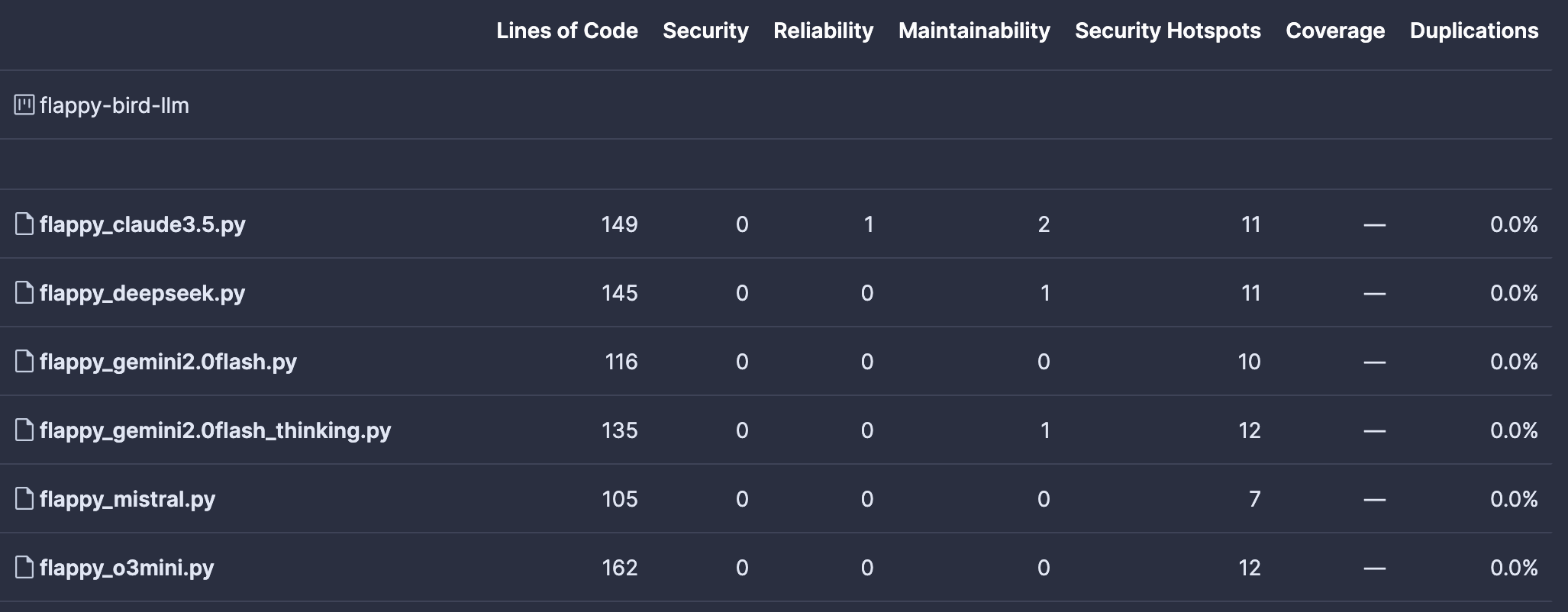
The Security Hotspots flagged by Sonar are related to random number usage and can be disregarded.
While direct comparisons are challenging, Gemini 2.0 Flash Thinking stands out when considering both speed and quality. Claude 3.5 performs well, though Sonar detected slightly more code quality issues—albeit minor ones—in this small example.
Regarding gameplay experience, which is more subjective to measure, the DeepSeek R1 and o3-mini versions proved the most enjoyable due to their balanced difficulty. Claude 3.5's version was a bit too slow, while Gemini 2.0 Flash Thinking's was exceptionally challenging. Mistral's version played well until losing when the bug appeared.

Summary and Takeaways
The LLM market is experiencing rapid evolution and intense competition in early 2025, with several key developments shaping the landscape:
Google's Comeback with Gemini 2.0: Offering unprecedented context windows (up to 1M tokens), competitive pricing (90% cheaper than competitors), and strong performance in coding tasks.
Disruption of Traditional Software: LLMs are challenging established tools, particularly in OCR, with Gemini 2.0 Flash processing 6,000 pages per dollar at high accuracy.
Local Deployment Challenges: While possible, local deployment faces hurdles with GPU requirements and model compression. Dynamic quantization shows promise as a potential solution.
Specialized Excellence: Different models excel in specific niches—le Chat for speed, Gemini for context handling, and DeepSeek for open-source capabilities.
Key Takeaways:
Companies should focus on finding the right model for their specific use case rather than chasing leaderboard positions.
The rapid pace of innovation makes it crucial to evaluate the timing and benefits of model transitions carefully.
Performance testing is essential, as demonstrated by the Flappy Bird experiment, where Gemini 2.0 Flash Thinking showed impressive speed and quality.
The market will likely evolve rapidly throughout 2025, with improvements in local deployment solutions and potentially new hardware innovations.