
Latest LLM Models & Value Analysis
This post is about navigating the Latest LLM Models, Engineering Skepticism, and the Business Reality.

In the last few days, we've seen major announcements in the GenAI world from the two biggest players: Anthropic with their new development-focused model Claude 3.7, and OpenAI with GPT 4.5.
What's interesting is that the dust seems to be settling. More and more voices on Reddit, LinkedIn, and other social platforms appear unimpressed with the new models, suggesting we've hit a limit on what larger models can achieve. Pricing for these models has also increased, despite expectations that DeepSeek would prevent such price hikes.
Even as models evolve, we continue to see many developers who remain skeptical about what LLMs can accomplish, while others oversimplify their capabilities.
This makes decision-making even harder for companies:
Should they invest in such expensive tools for everyone?
If so, what's the return?
Can this gain actually be quantified in real numbers?
Latest developments
Claude 3.7
According to the SWE-bench Verified benchmark, Claude 3.7 Sonnet achieves 62.3% accuracy. This is impressive, as competitors like o1, o3-mini, or DeepSeek only reached around 48-49%.
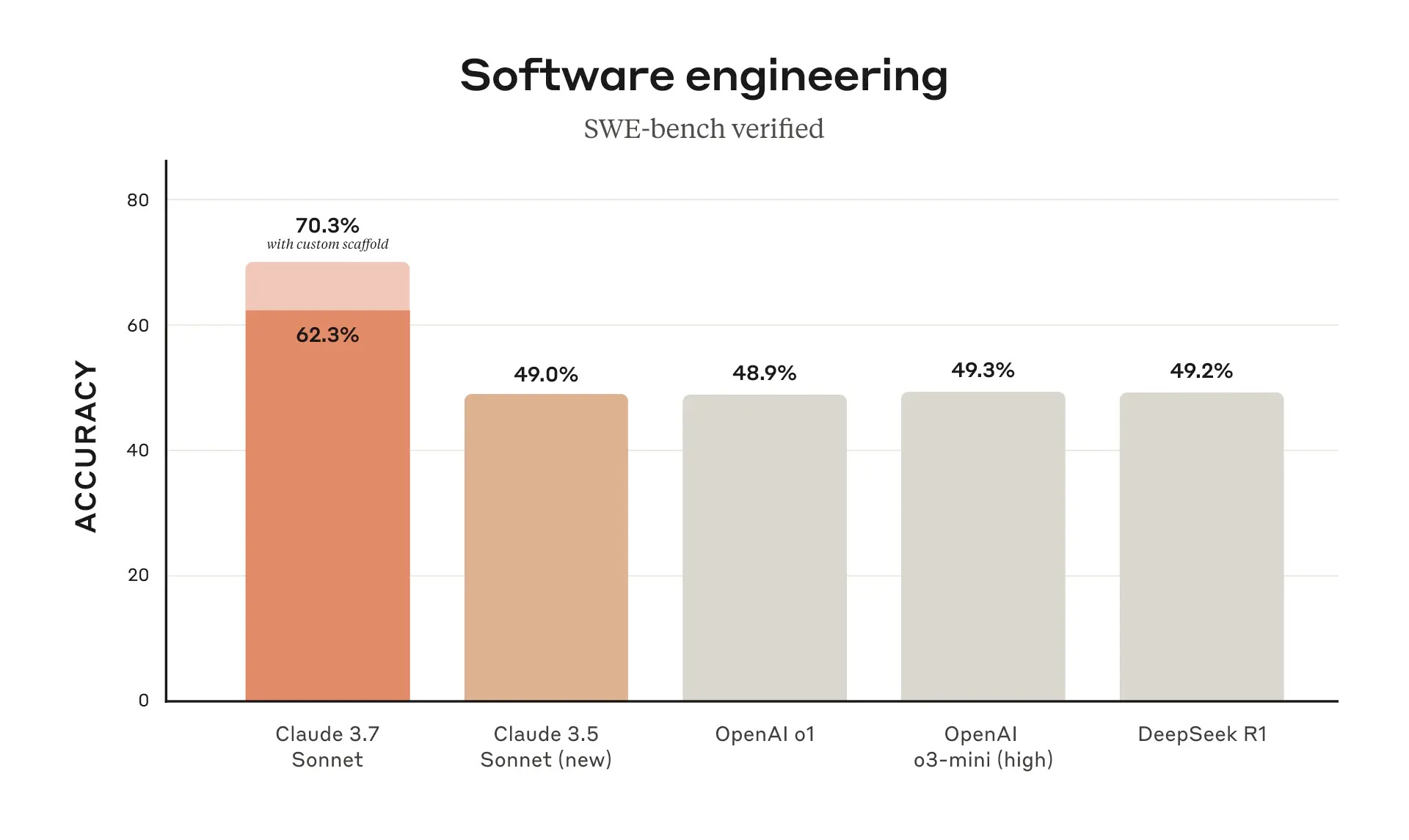
This test includes a couple of coding tasks whose accuracy is also in dispute, but it's better than nothing. Companies that have already used Claude 3.7 have noted that it can create production-ready code with fewer errors. However, Reddit posts and other tests paint a different picture, with people not impressed by Claude 3.7's coding performance.
Anthropic explicitly focused on coding with this model and delivered a CLI-based agentic coding assistant called Claude Code. This tool is extensive in its usage as it tries to understand the code and takes a multi-step agentic approach. It doesn't stop with just the typical one-prompt-one-response pattern but also checks if:
the application is running
whether tests have been written
and more—all in one go
The problem now is pricing. It's similar to previous models at $3 per million input tokens and $15 per million output tokens, but as a reasoning model, it will need many more tokens. When using Claude Code, always monitor your spending, as it can easily work on specific tasks for quite a while and consume a lot of tokens during that time.
GPT 4.5
There has been a lot of hype around OpenAI. As the first company to introduce such models to the market, there's always excitement when OpenAI releases something new. Perhaps GPT 4.5's mixed reception isn't the model's fault but rather due to overhyped expectations. GPT 4.5 doesn't particularly impress on technical benchmarks, though it does seem to excel in more human-like responses—what's often described as "vibe" tests. This focus on conversational quality matters for text generation but isn't as crucial for coding tasks.
It's also reportedly a very large model from a training perspective. Despite having "Open" in its name, OpenAI is completely closed, with limited information about the model's actual size. Estimates range from 5 trillion to 12.8 trillion parameters. The pricing is extreme: $75 per million input tokens and $150 per million output tokens. It's only available to those with the Pro version of OpenAI at $200 per month, making it inaccessible to most users.
Looking at the value proposition confirmed by users so far, the results seem diminishing considering the costs:
✅ Reduced Hallucinations
✅ Enhanced Conversation Abilities
✅ Improved Reasoning and Knowledge
But on the other hand:
❌ The returns are small, especially considering the amount of money used to train this model
❌ There is simply no value proposition. It is not better in coding or any other benchmark
If OpenAI were a publicly traded company, its stock would likely have dropped significantly since GPT 4.5's release. However, we'll have to wait and see—perhaps they have more innovations coming in the months ahead.
Value proposition for engineers and Tech companies
Engineers
So what do engineers get out of LLMs today? I see a lot of discrepancies. Some engineers claim they can change the world with LLMs, while others say they're useless and create too many errors. As usual, the truth lies somewhere in between.
LLMs are extremely good at understanding a system and building one from scratch. They can speed up development if you want to start something new or hash out a prototype. But by what factor? This is where it becomes a training issue. If you understand how these LLMs work and their limitations, you know how to work around them. I struggled to give people a good example for some time, but let's compare them to human beings.
Before it gets odd, hear me out. A human has limited capacity before we actually tend to hallucinate or forget things. We're very good at storing information and taking time to work through things step by step, which limits these issues. This is basically what reasoning models do, but more importantly, we need context. Let's take a typical software project with moderate complexity with almost no documentation. Now you add some stories you should deliver, and part of the company—or even the team—provides a poor description of what needs to be done and how. How long do you think the engineer will take? How does this compare to a project with the same complexity but with:
Extensive documentation
Thorough onboarding materials
Very detailed stories and technical architectures
Of course, without thinking, we know which project is more effortless and where engineers will have faster impact on the code. Guess what? LLMs work the same way. If you give them more context—to the extent they can cope—they will provide better results.
I still see messages on LinkedIn or other social networks where people complain that an LLM cannot correctly count the number of Rs in "Strawberry." By the way, they typically ask with just one sentence, without providing more context about what the LLM should do.
If you get the point, you understand that those who are good at writing and describing things become better users of GenAI because they already understand that describing a problem—not always with a lot of words, but precisely and with enough context—is exactly what's needed.
If you struggle with that, well, guess what? You can use LLMs to help you.
Here's a simple example to start something from scratch, which I created to have a FSN dashboard for all field safety notices in medical software:
Please write a design brief that i can give to my ai coding assistant for this: "I need a dashboard KPI page to track FSNs over companies and products from a JSON. Each JSON entry looks like that
{
"product": "ORBIS Medication",
"company": "DH Healthcare GmbH",
"date": "11. Februar 2025",
"title": "Dringende Sicherheitsinformation zu ORBIS Medication von DH Healthcare GmbH",
"category": "Medizinische Datenverarbeitung (Software) - Sonstiges",
"reference_number": "04401/25",
"link": "<https://www.bfarm.de/SharedDocs/Kundeninfos/DE/09/2025/04401-25_kundeninfo_de.pdf?__blob=publicationFile>"
},
I want to have charts to track by Company and deep dive when multiple products are listed for one company. I also want to a overview chart over time which I can adjust. When I can see a single entry I want to have a link to the PDF.
I also want to have a overview page over all entries in a table form where I can search by product, company, category, reference_number and date.
I need to be able to see if some companies have more incidents then others and if some products are more effected then others. I also want to be able to compare multiple companies and products."
Instead of using this as a direct entry point to code something, I explicitly tell it to create a design brief that I can give to my AI coding assistant.
This creates something like:
**Design Brief: FSN KPI Dashboard**
### **Objective**
Develop a KPI dashboard to track Field Safety Notices (FSNs) over companies and products based on JSON data. The dashboard should provide insights through visualizations and searchable tables, allowing deep dives into company and product trends.
### **Data Structure**
Each FSN entry follows this JSON format:
```json
{
"product": "ORBIS Medication",
"company": "DH Healthcare GmbH",
"date": "11. Februar 2025",
"title": "Dringende Sicherheitsinformation zu ORBIS Medication von DH Healthcare GmbH",
"category": "Medizinische Datenverarbeitung (Software) - Sonstiges",
"reference_number": "04401/25",
"link": "https://www.bfarm.de/SharedDocs/Kundeninfos/DE/09/2025/04401-25_kundeninfo_de.pdf?__blob=publicationFile"
}
```
### **Key Features**
#### **1. Dashboard Overview**
- **Company-Level Analysis:**
- Aggregated FSN count per company.
- Ability to drill down when multiple products exist for a company.
- **Product-Level Analysis:**
- FSN count by product.
- Comparison of affected products across different companies.
- **Time-Based Analysis:**
- Adjustable time range filter.
- Line chart for FSNs over time.
#### **2. Entry-Level Details**
- Clickable FSN entries with a link to the provided PDF document.
- Detailed view of a single FSN entry.
#### **3. Searchable Table View**
- Table containing all FSN entries.
- Search and filter functionality based on:
- Product
- Company
- Category
- Reference Number
- Date
#### **4. Comparison Features**
- Compare multiple companies and products to identify trends.
- Visualize which companies have higher FSN counts.
- Identify products with the most safety notices.
### **UI & UX Considerations**
- **Charts & Visuals:**
- Bar charts for company and product FSN counts.
- Line chart for FSNs over time with adjustable date range.
- Interactive filters for dynamic data exploration.
- **Table Layout:**
- Paginated and sortable.
- Searchable with multiple filters.
- **Navigation & Usability:**
- Clear layout with an overview page and detailed views.
- Clickable elements for deep dives.
### **Technical Requirements**
- Backend or frontend processing of JSON data.
- Charting library (e.g., Chart.js, D3.js, Recharts) for visualizations.
- Table component with search and filtering (e.g., DataTables, AG Grid, React Table).
- Responsive design for desktop and mobile usage.
### **Deliverables**
- A fully functional dashboard with:
- Overview KPIs and charts
- Searchable table
- Deep-dive capability into company and product details
- FSN entry details with PDF links
- Clean and maintainable code structure.
Now, depending on your tool of choice, you can start working with that. If you use an agent, it's even easier—copy and paste that design brief and give it to your coding AI assistant like Replit or Claude Code and go from there. These AI agents will work on the problem until they have a working solution, which saves tons of time.
If you dislike writing, check out the post at

and try a tool like SuperWhisper, which enables coding through voice commands or AI agents.
The same principle applies to existing code. Always provide the AI with sufficient context about your goals. For example, with build pipeline optimization:
Don't just share the workflow file and ask for improvements
Take a more methodical approach: first analyze the logs with an AI
Use those insights when sharing your workflow file
Explain your issue, previous attempts, and desired outcome
Request that the AI create a design brief for pipeline optimization
This multi-step process yields tangible results, whereas expecting a perfect solution in one shot typically fails. Like humans, AI doesn't instantly have all the answers—it needs to explore multiple sources and understand the problem and preconditions before solving it effectively.
It's still astonishing how many people expect AI to understand everything from just a few words and become frustrated when it fails.
That's my value proposition for engineers regarding AI—there definitely is one. If you haven't discovered it yet, experiment with it to understand how it can benefit your workflow.
Companies' Value Proposition
This is more complicated because companies expect something from AI—most commonly, time savings that ultimately create an ROI as developers code more efficiently and can redirect their efforts elsewhere. All monetary ROIs from AI revolve around this principle, as it's the only tangible return you can measure. The challenge lies in measuring this effectively, especially since AI implementation isn't straightforward, as I tried to convey in the previous section for engineers. It's not merely about tool onboarding—it's about:
Learning to use LLMs efficiently
Understanding both their limitations and benefits
Staying current in a field that changes every few weeks
Keeping up with the growing knowledge base created by others exploring new applications for LLMs
Some companies seek concrete metrics to demonstrate improvements or survey their developers about time savings. However, this approach rarely yields accurate results. Engineering isn't factory work where optimizing a production line increases output. As knowledge work, it involves complex human interaction and cognitive effort. AI may help more in some scenarios than others. Even something as simple as a company's tech stack might determine whether AI delivers better results in one organization versus another. This is further strengthened by external research from PWC indicating that performance gains from GenAI can vary from 20% to up to 50%.
I've also heard that US-based companies and those led by technical CEOs aren't asking these questions. They use GenAI because they know reducing friction in their development process pays off. Engineers are very expensive, and if they can utilize their time better with GenAI, it's an obvious decision for technical leaders—requiring little deliberation.
In other companies, we see different challenges. GenAI is expensive, and understanding how development bottlenecks affect your engineering pipeline is crucial. These bottlenecks are also hard to measure, so that you won't find a perfect measurement approach—but why do you need that? In a time when salaries are expected to rise and technical talent remains scarce, it should be an easy decision to make.
Overall, I expect companies using GenAI for development to see positive impacts. It will take time, but organizations with early access will gain advantages in their engineers' training and onboarding curve. Companies with simpler architectures and better documentation will also have an advantage, as LLMs will more quickly grasp and correctly understand what needs to be done.
Conclusion
Throughout this article, we've explored the latest advancements in LLM models, examining their strengths, limitations, and practical applications for developers. We've seen that despite some lingering skepticism among developers about coding capabilities, there is undeniable value in these tools when used strategically.
Recap for Engineers
For engineers, GenAI's value proposition lies in its ability to serve as a collaborative partner in the development process. We've learned that providing sufficient context is crucial for obtaining high-quality outputs. Just as humans perform better with proper documentation and clear requirements, LLMs deliver more accurate results when given comprehensive context about the problem. The most successful engineers will be those who can effectively communicate their needs to these AI systems and integrate them thoughtfully into their workflows.
Business Value Assessment
For companies, while measuring the exact ROI of GenAI implementation remains challenging, the potential benefits are substantial. According to research from PWC, performance gains can range from 20% to 50%. In a competitive landscape where technical talent is scarce and expensive, organizations that embrace these tools early stand to gain significant advantages in:
Productivity
Knowledge sharing
Innovation acceleration
Future Outlook and Transformative Potential
Industry analysts project continued adoption growth, with Gartner predicting that by 2028, 75% of enterprise software engineers will use GenAI assistants. This widespread adoption will likely accelerate as the technology matures and best practices become more established. Early adopters are gaining valuable experience and competitive advantages that may prove difficult for laggards to overcome.
The emergence of an "idea economy" represents one of GenAI's most intriguing potential futures. As these tools reduce the production costs for getting ideas off the ground, companies can expect a more democratic and open environment where good ideas can compete more effectively regardless of origin. This democratization may fundamentally alter innovation dynamics within and between organizations.
Some technologists anticipate that GenAI will eventually automate or augment every stage of software development, potentially making current methodologies like Agile obsolete as development processes reorganize around AI capabilities. While this prediction remains speculative, it highlights the potentially transformative impact of these technologies beyond mere productivity improvements.
In the future, we will likely see increased integration between GenAI coding tools and other enterprise systems, creating more seamless workflows across business functions. This integration may enable entirely new classes of applications and services that weren't previously feasible due to development constraints.